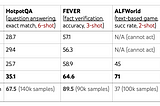
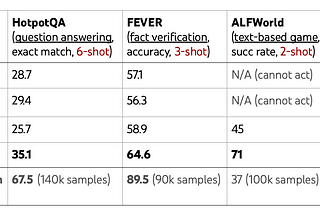
Jake BatsuuriAnalyzing ReAct: Synergizing Reasoning and Acting in Language Models PaperRe-asoning and Act-ing SynergisticallyNov 20, 2023Nov 20, 2023
Jake BatsuuriinComputronium BlogText SegmentationNormalization, Tokenization, Sentence Segmentation + Useful MethodsAug 27, 2021Aug 27, 2021
Jake BatsuuriinComputronium BlogInputting & PreProcessing TextInput Methods, String & Unicode, Regular Expression Use CasesAug 25, 2021Aug 25, 2021
Jake BatsuuriinComputronium BlogWhat are Context Free Languages?Grammars, Derivation, Expressiveness, Chomsky HierarchyJul 27, 20211Jul 27, 20211
Jake BatsuuriUsing Lexical Resources EffectivelyFrequency Distributions, Wordlists, WordNet, Semantic SimilarityJul 19, 2021Jul 19, 2021
Jake BatsuuriinComputronium BlogLanguage Generation with Recurrent ModelsLSTM, Sampling, Smart Code Completion ToolMar 21, 2021Mar 21, 2021
Jake BatsuuriinComputronium BlogLanguage Processing with Recurrent ModelsBidirectional RNNs, Encoding, Word Embedding and TipsMar 16, 2021Mar 16, 2021
Jake BatsuuriinComputronium BlogRecurrent Models OverviewRecurrent Layers: SimpleRNN, LSTM, GRUMar 15, 2021Mar 15, 2021